One Dynamics One Platform : Analytics - Delta Lake Synapse Link

Update September 2023 : The F&O part is now in General Avaibility (GA)
Hello the Community !
Hope you had a good summer holiday, starting next season's articles, it was time for me to write this new article to explain again the convergence of the whole Dynamics Platform : on the Analytics part now !
For the analytics part; we had only Synapse Link Dataverse (Exporting CSV) and also 1 specific part for F&O (Export Data Lake LCS , and no Synapse Link, CDMUtil was needed back then - See the Github Repo of Fast Track team for that)
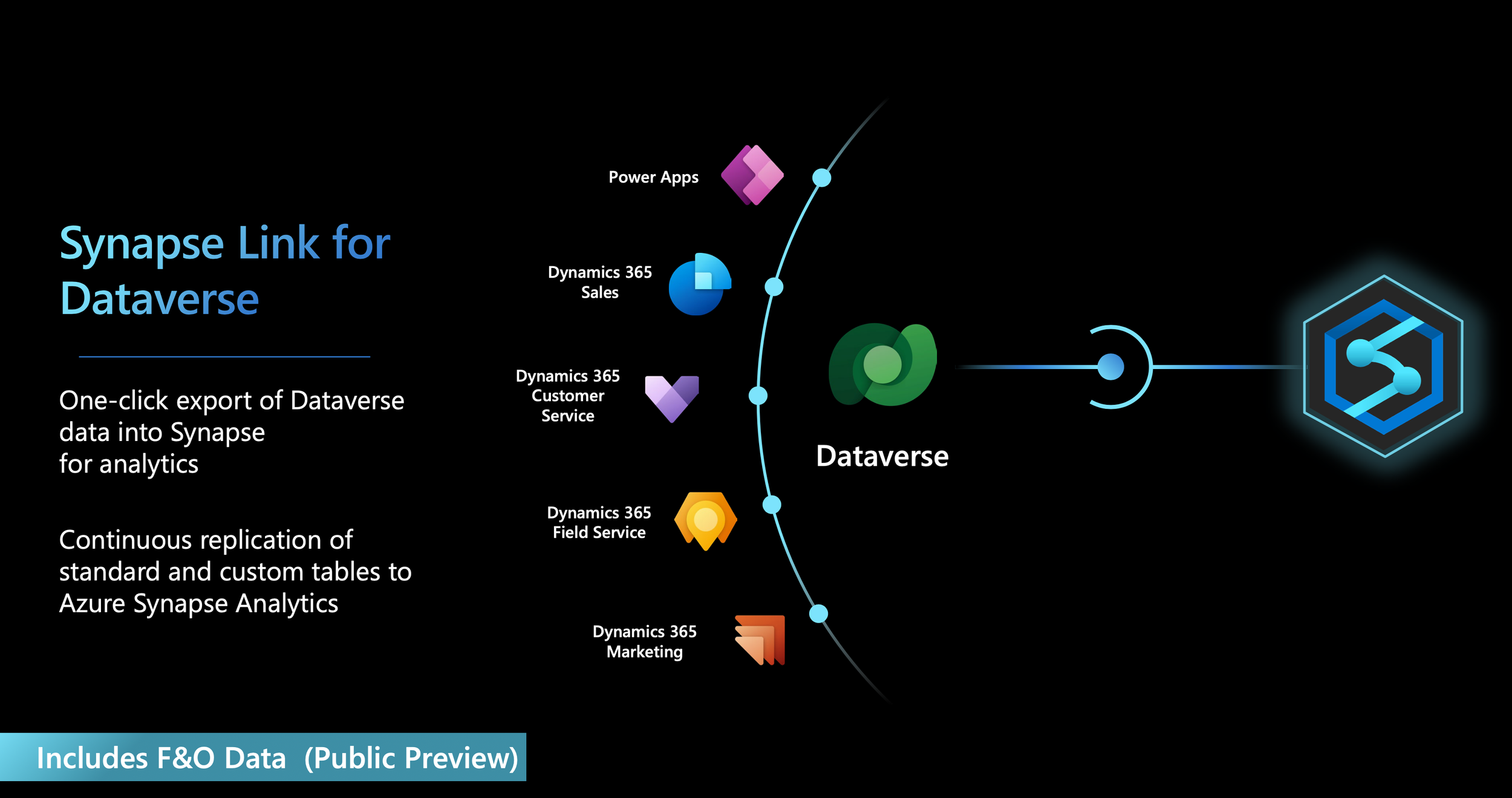
Now we have 1 Feature globally that lets you export both data (coming from CE or F&O) on Dataverse side via Synapse Link and Delta Lake / Parquet format (Apache Spark Cluster) and that is what I will show you now, let’s jump in !
Introduction
A few quick elements of definition/vocabulary
A Delta Lake is an open-source storage layer designed to run on top of an existing data lake, improving its reliability, security, and performance. Delta Lakes supports ACID transactions, scalable metadata, unified streaming, and batch data processing.
A data lakehouse is a new open architecture that combines the flexibility and scalability of a data lake with the data structures and data management capabilities of a data warehouse.
Lake databases use a data lake on the Azure Storage account to store the data of the database. The data can be stored in Parquet, Delta or CSV format and different settings can be used to optimize the storage. Every lake database uses a linked service to define the location of the root data folder
Apache Spark is a unified, lightning-fast analytics engine for large-scale data processing. It allows large-scale analyzes to be carried out through Cluster machines. It is mainly dedicated to Big Data and Machine Learning.
Synapse Link enables you to run analytics, business intelligence and machine learning scenarios on your operational data with minimum impact on source databases in almost real-time with a new change feed technology.
Synapse Link Dataverse via Apache Spark / Delta Lake format (storage as parquet files) is in GA from June 2023 (just after MSFT Event Build 2023) - F&O data is in Public Preview, target GA is for the end of this year.
The serverless SQL pool in Synapse workspace enables you to read the data stored in Delta Lake format, and serve it to reporting tools. A serverless SQL pool can read Delta Lake files that are created using Apache Spark, Azure Databricks, or any other producer of the Delta Lake format.
Apache Spark pools in Azure Synapse enable data engineers to modify Delta Lake files using Scala, PySpark, and .NET. Serverless SQL pools help data analysts to create reports on Delta Lake files created by data engineers.
Why use Delta Lake?
Scalability: Delta Lake is built on top of Open-source Apache license, which is designed to meet industry standards for handling large-scale data processing workloads.
Reliability: Delta Lake provides ACID transactions, ensuring data consistency and reliability even in the face of failures or concurrent access.
Performance: Delta Lake leverages the columnar storage format of Parquet, providing better compression and encoding techniques, which can lead to improved query performance compared to query CSV files.
Cost-effective: The Delta Lake file format is a highly compressed data storage technology that offers significant potential storage savings for businesses. This format is specifically designed to optimize data processing and potentially reduce the total amount of data processed or running time required for on-demand computing.
Data protection compliance: Delta Lake with Synapse Link provides tools and features including soft-delete and hard-delete to comply various data privacy regulations, including General Data Protection Regulation (GDPR).
Config / Dataverse
To start our journey of configuration, you can also refer to this MS Learn How-To (be careful F&O folks, globally you will need to do this too !) - So please read it, and yes we are on the ODOP (One Dynamics One Platform : convergence - so Power Platform is everywhere)
You’ll need an Azure Subscription for this purpose. Before even going further I will suggest checking 1 important thing which is not documented at all (yet), I open up a GitHub issue here for Microsoft to change the documentation.
By default, on a lot of Azure subscriptions, you’ll have a default limit/quota of the number of vCore available for Apache Spark in Azure Synapse Analytics (12 if I remember well) but Delta Lake format will need 20 in minimum so fail every time. The bad part is in fact the job will even not start and you will not see anything in the Apache Spark applications running in Synapse studio…
“I think you should add to check if the Azure Subscription don't have a limit of 12 vCore available per Workspace for Apache Spark. Since, Synapse Link requests each time minimum 20 vCore, it will fail every time. (no matter the config you choose: small, medium, nodes etc...)
My side I add to open a SR to Microsoft to increase the quota.”
So besides that, it’s quite easy to do.
So first, you will need to create an Azure Data Lake Storage Account V2. You will need to be Owner and Storage Blob Data Contributor role access. Your storage account must enable Hierarchical namespace and public network access. But again I explained already in my previous article on how to create an ADLS V2, it’s quite simple to do so.
After, you’ll need to create your Azure Synapse Analytics. And of course, let’s check the limit I spoke about before. You must have Owner role in access control(IAM) and the Synapse Administrator role access within the Synapse Studio. The Synapse workspace must be in the same region as your Azure Data Lake Storage Gen2 account (including the same region as the dataverse too)
Then, create the Apache Spark that you can check here too.
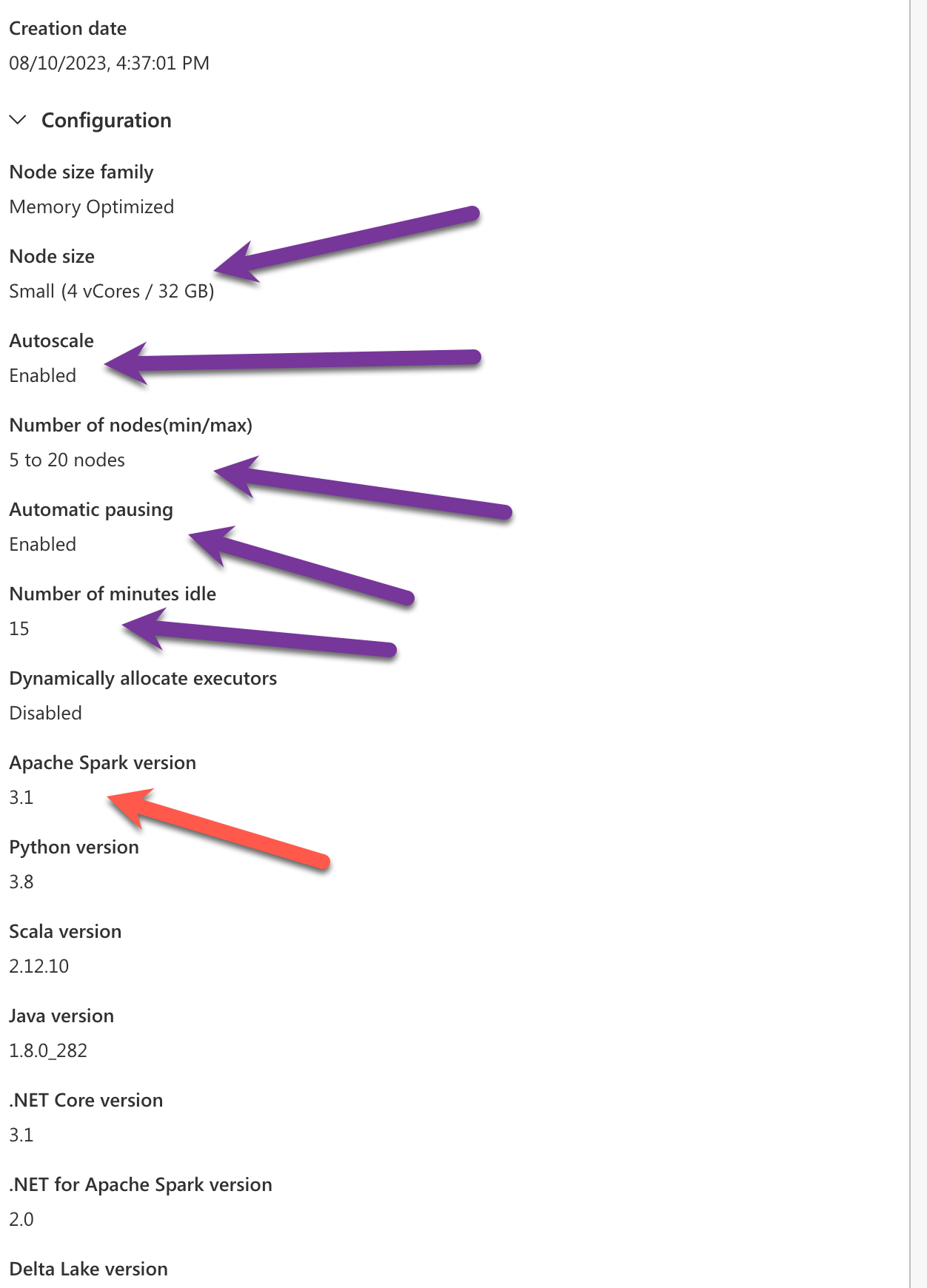
My side I choose this type of configuration that is enough to start.
Be careful of the Apache Spark, 3.1 is required and not 3.3 (Don’t know why Apache Spark 3.3 is not supported yet, while 3.1 is in EOL now… / Update : The Spark 3.3 version will be supported in Oct-2023) - For the rest Small size is enough to start, but put a good number of nodes with an AutoScale part. Of course in production, you’ll need to check the telemetry to see if you can reduce or increase it. That depends on your data volume on how many times/tables you’ll extract. That’s a fine tunning part.
You are ready to go to the config part in Dataverse. Quite fast for the Azure part right ? :)
So go the maker portal of Power Apps ; to the right Dataverse environment you want.
Please be aware that the config part of Synapse link is solution-aware, which means export/import and ALM part. (DEV, QA , PROD)
Choose the good Azure subscription, Azure RG, Azure Synapse Workspace, Apache Spark. Note the region here of your Dataverse again and also azure resources need to be in the same location.

You’ll see after the last part of config, the tables to select you want to have and also. Please check the advanced part (refresh interval, you can reduce it to 15 minutes, by default it’s 60)
If you have an error on the App “Insights Apps Platform Prod “ the first time it’s normal, it’s because 1st time in the tenant, Microsoft needs to push their Enterprise Application into Azure AD. Just retry again a few seconds after and it will work.

Of course the tables can be change too after when it’s already running. You can unlink at any moment and remap it if you like.

If you go to Synapse again, you’ll see your Lake Database, and you can query your table(s) - check also that all Choice/OptionSet/Enum are there too by default. Query use Serverless on top of the Delta Lake / parquet format which in my case is running every 15 minutes.

To check Apache Spark Application jobs, you can go to Synapse here :
You can see that a batch job will run every day too for maintenance job (Delta Lake)

In the Data Lake, you’ll see something like this (in parquet) :

Last, you can check also every apache spark batch job on the Spark UI interface for logs/monitoring etc…

Config / F&O
Hey ERP , F&O folks, now is your part. So again, since we are talking about convergence, the config part Dataverse I explained before is important because you need to do the same config, the last “particular” part is here for F&O
If you want, you can read the article on MS Learn too here :
First, in F&O it’s in Public Preview yet. So, assuming also that you are already into a TIER2 instance of F&O linked already into a Dataverse environment too. (1:1)
For the link I’ll highly suggest to read my last article here.
Also, I will highly suggest to be part of the Yammer/Viva Engage Group here
F&O TIER2 instance (and future in GA production) needs to be at least in 10.0.34 or more.
At the moment of the public preview, a configuration key in F&O need to be activated. At some point, it will be activated by default. Put the environment in maintenance mode for that and tick “SQL row version change tracking”

Please see the actual limitations as of August 2023 ; some of them will change before reaching GA.

As you can see, you can’t have / use the same Azure Synapse Link you have also for CE tables too (same one creating 1 global Lake Database) - so now it will be seperated.
You can activate also your custom tables too, in this case you have to enable change tracking on those ones.
Delta Lake is mandatory, that’s why I started this article to explain how it works in general for Dataverse side.
The initial refresh (but I didn’t see such poor performance yet) or the number of tables will be improved, so not a big deal.
So assuming the config is good on your side, you can go the this specific link meanwhile during preview only. (last part of arguments is important) - Environment Id is the dataverse linked to your F&O instance.
https://make.powerapps.com/environments/<environment ID>/exporttodatalake?athena.enableFnOTables=true

As you can see ; you can see F&O tables and export them ; easy right ? and no CDM Util !!

As you can see, like Dataverse / CE tables, FnO is partionned by Year by default, so help a lot on the performance (besides the fact we are now on Delta Lake, including parquet format) . So despite the fact CDM util is not needed anymore, query performance and Serverless SQL Synapse cost will be highly reduced too. So globally, even if you’ll have also a cost on the Apache Spark cluster that will run every time to create parquet file behind the scene, the data processing that we have before with the CSV standard export data lake in LCS will be highly reduced so the total cost of Synapse / Data architecture in general.
But now, you will say what about Data Entities in F&O ?
Well, no worry, Microsoft has done that too. But how? Well, by Virtual entity of course ! So that’s why my previous article is important to read again… :)
I will not repeat because the MS Learn doc is quite good for that, globally :
Activate the data entity of F&O as virtual entity into the dataverse
You will have the table in dataverse as mserp_xxxxx
Put this table into a Solution of this dataverse, and change the property to be change tracking aware.
You can export this table as “normal” table as explained before into Synapse Link

Same as before in Synapse Studio, you can check your Lake Database and query the table you have exported

Conclusion
In terms of benchmark & conclusion, what I can tell you now ?
in terms of performance, I see especially for F&O large tables or especially complex query/view a 50% decrease of the time of the query elapsed time ! That huge, and also the amount of data processed have been reduced by 75% (like a global cost of Synapse TB Serverless 25 TB in CSV a day because of 45 reports PBI refreshed every hour in Power BI Premium Per User, I have now the same thing for 5TB per day) ; so 100€ a day (because 4€ per TB) is now 20€ a day ! (NB : please check also that your reports are using - if import data mode and not direct query - in Power BI an incremental refresh !)
In terms also for administration, no CDMUtil for F&O, a better & simplified procedure (hopefully activating data entity in F&O into Dataverse as virtual table will be simpler at the end), taking advantage of the same feature as CE People with Dataverse, it’s huge believe me ! Finally, when you talked with Data Specialist in MSFT platform, when you said Parquet / Delta Lake they smile, if you say CSV, they cry !
Microsoft Fabric

For this part, you’ll have to wait a little bit, I will write a new article in the coming weeks, while it’s still in preview and need to be tested by my side, I found some bugs yet :) but the global concept will be like this :

Update Feb 2025 : I have created now a dedicated article for Fabric Link with Dynamics 365 !
Demo / Video
See you next time ! Hope you like it, feel free to see my demo/video/how-to and share it 😁