Azure Data Lake with Dynamics365 FinOps - CustomerInsights and Power Platform !
Hello the Community ! Between some webinars and also some Events, I wanted to share something special for you : Azure Data Lake in all its glory !
1. Data Lake Designed for enterprise big data analytics
Data Lake Storage Gen2 makes Azure Storage the foundation for building enterprise data lakes on Azure. Designed from the start to service multiple petabytes of information while sustaining hundreds of gigabits of throughput, Data Lake Storage Gen2 allows you to easily manage massive amounts of data.
A fundamental part of Data Lake Storage Gen2 is the addition of a hierarchical namespace to Blob storage. The hierarchical namespace organizes objects/files into a hierarchy of directories for efficient data access. A common object store naming convention uses slashes in the name to mimic a hierarchical directory structure. This structure becomes real with Data Lake Storage Gen2. Operations such as renaming or deleting a directory become single atomic metadata operations on the directory rather than enumerating and processing all objects that share the name prefix of the directory.
In the past, cloud-based analytics had to compromise in areas of performance, management, and security. Data Lake Storage Gen2 addresses each of these aspects in the following ways:
Performance is optimized because you do not need to copy or transform data as a prerequisite for analysis. The hierarchical namespace greatly improves the performance of directory management operations, which improves overall job performance.
Management is easier because you can organize and manipulate files through directories and subdirectories.
Security is enforceable because you can define POSIX permissions on directories or individual files.
Cost effectiveness is made possible as Data Lake Storage Gen2 is built on top of the low-cost Azure Blob storage. The additional features further lower the total cost of ownership for running big data analytics on Azure.

Get powerful data lake functionality at cloud scale
Azure Data Lake Storage Gen2 is a highly scalable and cost-effective data lake solution for big data analytics. It combines the power of a high-performance file system with massive scale and economy to help you speed your time to insight. Data Lake Storage Gen2 extends Azure Blob Storage capabilities and is optimized for analytics workloads
2. Data Lake with Common Data Model (CDM)

Data stored in accordance with the Common Data Model provides semantic consistency across apps and deployments. With the evolution of the Common Data Model metadata system, the model brings the same structural consistency and semantic meaning to the data stored in Microsoft Azure Data Lake Storage Gen2 with hierarchical namespaces and folders that contain schematized data in standard Common Data Model format. The standardized metadata and self-describing data in an Azure data lake facilitates metadata discovery and interoperability between data producers and data consumers such as Power BI, Azure Data Factory, Azure Databricks, and Azure Machine Learning.
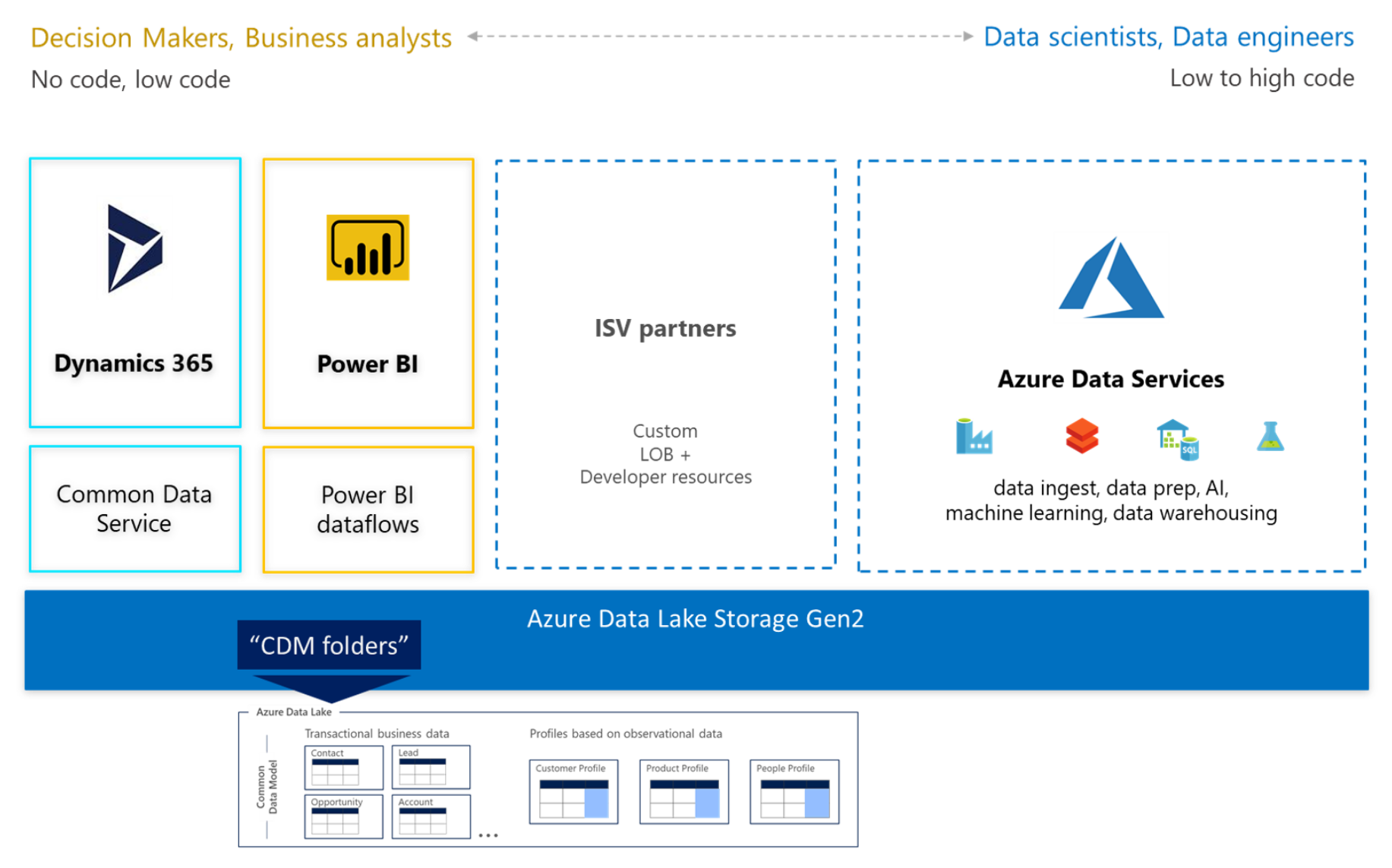
Common Data Model folders
Each Common Data Model folder contains these elements:
The model.json file
The model.json metadata file contains semantic information about entity records and attributes, and links to underlying data files. The existence of this file indicates compliance with the Common Data Model metadata format; the file might include standard entities that provide more built-in, rich semantic metadata that apps can leverage.
Data files
The data files in a Common Data Model folder have a well-defined structure and format (subfolders are optional, as this topic describes later), and are referenced in the model.json file. These files must be in .csv format, but we're working to support other formats.
The model.json metadata file provides pointers to the entity data files throughout the Common Data Model folder.
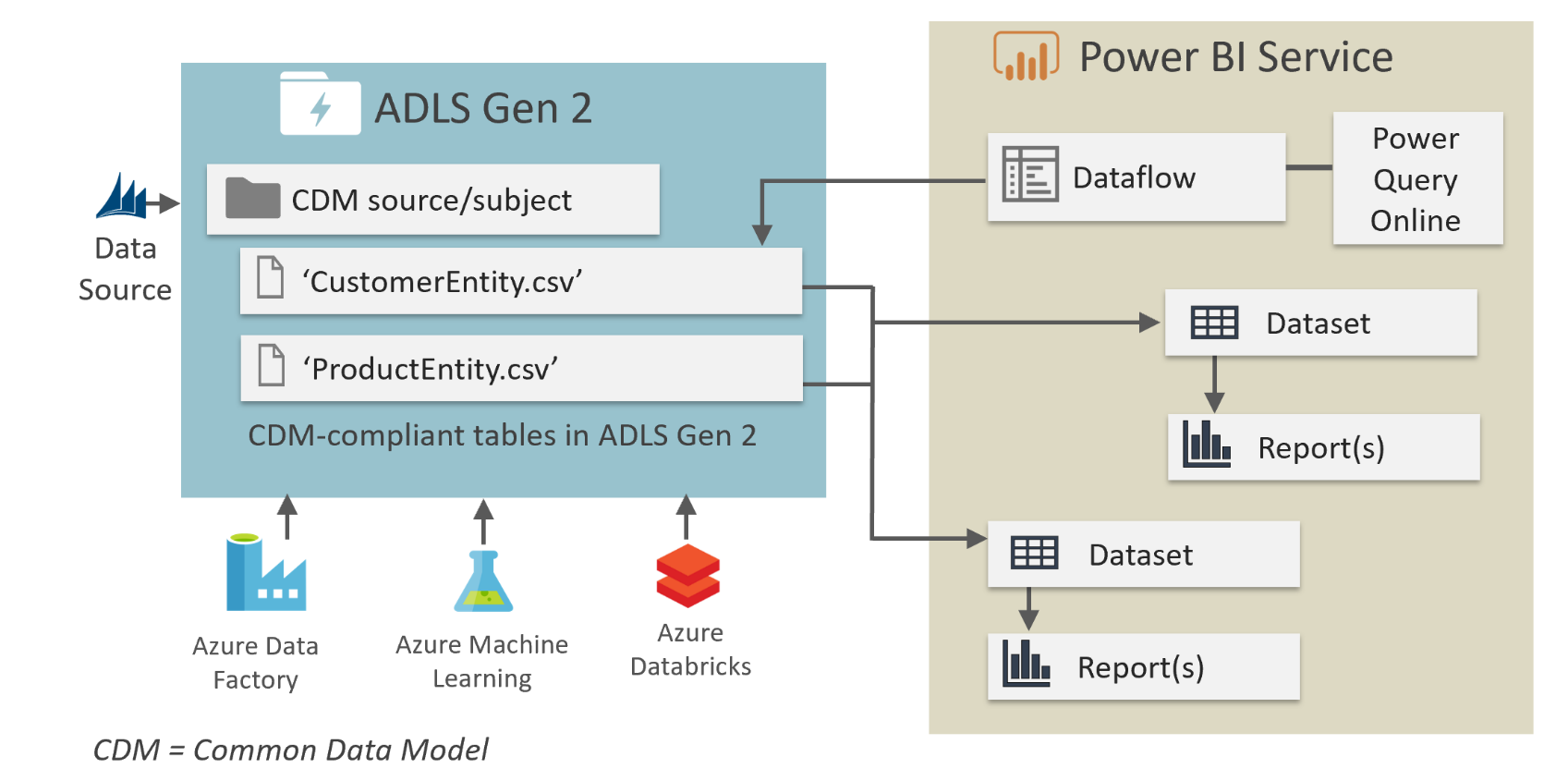
The following diagram shows an example of a Common Data Model folder created by a Power BI dataflow. The folder contains three entities.
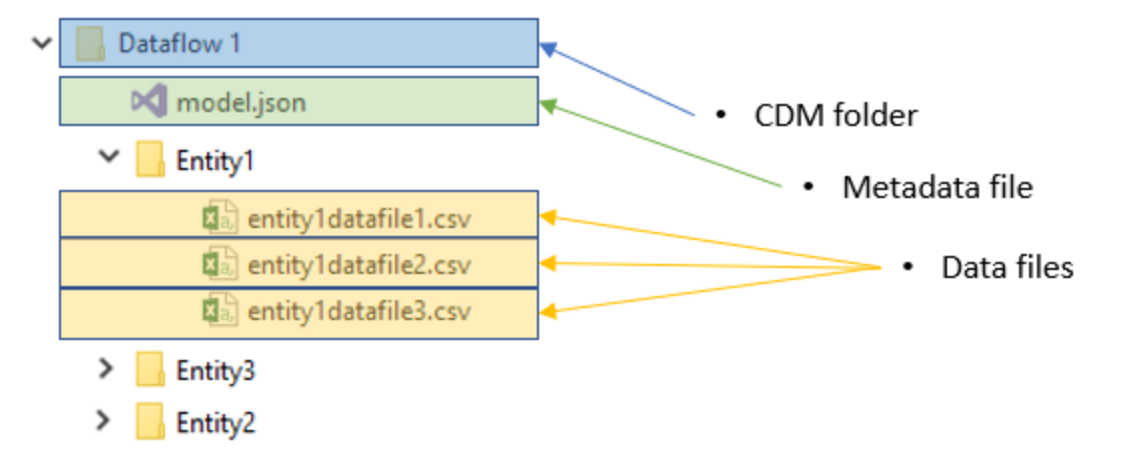
Folder organization
Data producers can choose how to organize the Common Data Model folders within their file system. You can create Common Data Model folders directly under the file system level, but for some services you might want to use subfolders for disambiguation or to better organize data as it's presented in your own product. The folder naming and structure should be meaningful for customers who access the data lake directly.
The following diagram shows how a data lake that data producers share can be structured. Each service (Dynamics 365, Dynamics 365 Finance, and Power BI) creates and owns its own file system. Depending on the experience in each service, subfolders might be created to better organize Common Data Model folders in the file system.

With the Common Data Model, you can structure your data to represent concepts and activities that are commonly used and well understood. You can query that data, reuse it, and interoperate with other businesses and apps that use the same format. The Common Data Model defines the size and shape of a Contact, for example, so that your app developers and business partners can parse that data and build your apps (or interoperate with other people's apps) with agility and confidence.
The Common Data Model is used within Common Data Service, which supports Dynamics 365, Power Apps, and the data-preparation capabilities in Power BI dataflows to create schematized files in Azure Data Lake. The Common Data Model definitions are open and available to any service or application that wants to use them.
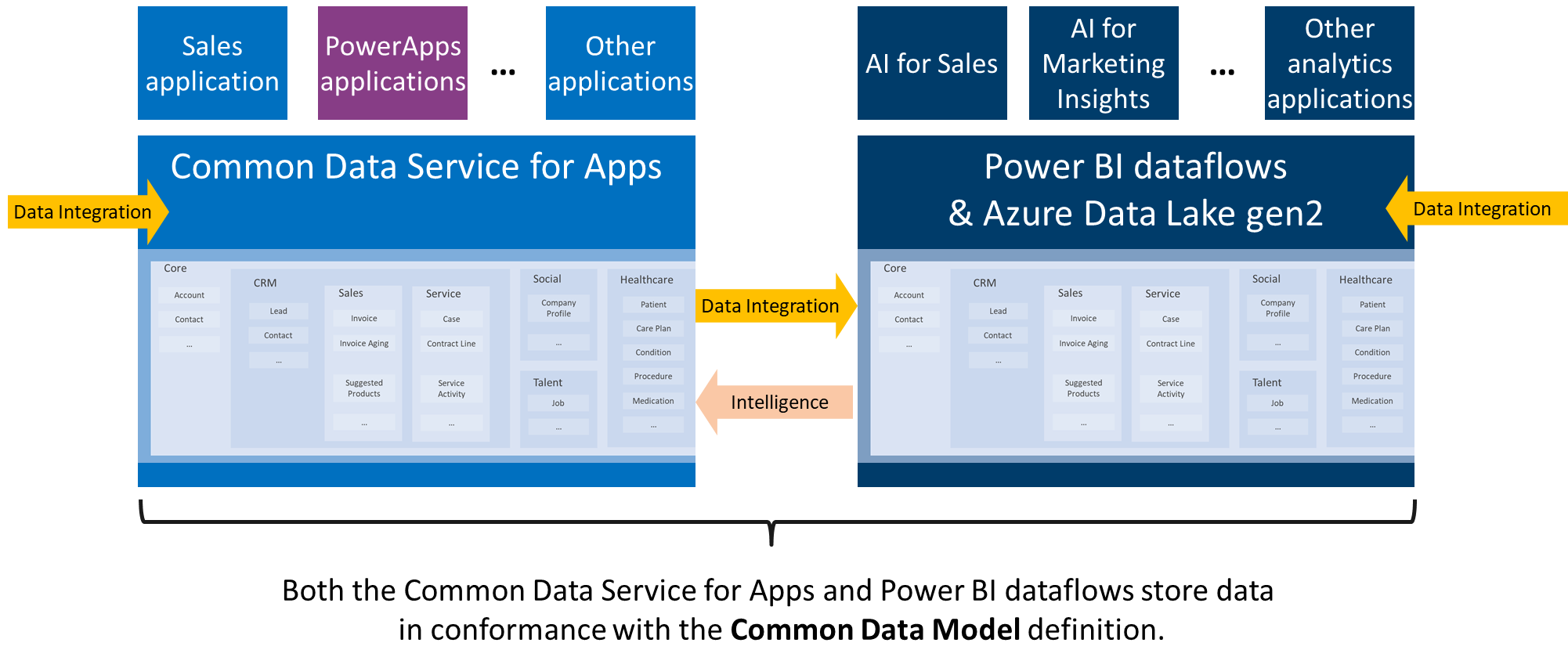
And so much more…

I can give you a lot of examples, but as you can easily thought, we can imagine a lot of things to bring with your CDM and CDS. It’s, like I described a lot, your MAIN storage for all your IT system ! For Dynamics, for PowerBI, for your PowerApps, PowerAutomate, for your CDS, for your DATA coming from SAP, Adobe, external CSV files, external connector, to prepare your DATA for AI, Azure ML, and all Azure Services are already connected to CDM and Azure Data Lake Storage (like Data Factory, Data Bricks, Azure Synapse Analytics (formely known as Azure SQL DW)

Finally, here are some CDM entities but as soon as you get a new Dynamics 365 Apps or creating a new PowerApps or whatever Business Apps you will have a common database with new entities (and you can create of course your own ones)
3. Create your own Azure Data Lake
As you will see it will be very difficult… :)
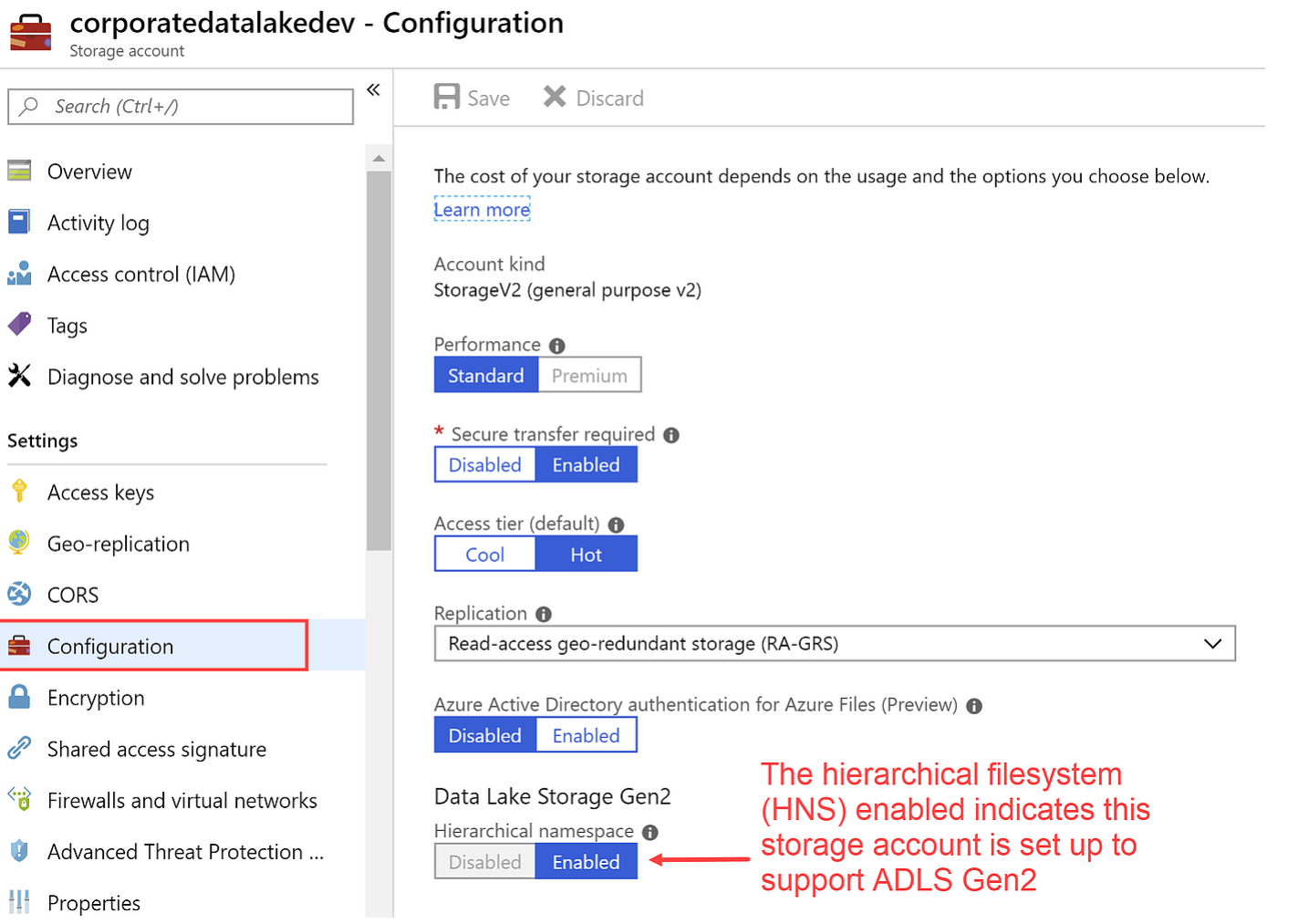
Just connect to your Azure portal, and create a new Storage Account.
The only thing complicated is to be careful to select the HNS namespace to “Enable” like this :
Now let’s give you some examples if you don’t mind….
4. Azure Data Lake with Dynamics 365 Finance and Operations
Entity store is an operational data store that is included with Microsoft Dynamics 365 Finance. This topic describes how Entity store enables Power BI integration.
Entity store is an operational data store that is included with the application. The Entity store feature was introduced in the Microsoft Dynamics AX platform update 1 (May 2016) release. This feature lets an administrator or power user stage aggregate measurements in a dedicated data store for reporting and analytics. (Aggregate measurements are a star schema that is modeled by using entities.) It’s a database that is optimized for reporting purposes. Entity store uses the in-memory, clustered columnstore index (CCI) functionality that is built into Microsoft SQL Server to optimize reporting and queries. Customers can use Microsoft Power BI DirectQuery models together with Entity store to enable high-volume, near-real-time analytical reporting over large volumes of data.

Now we can (since few months ago) store this Entity Store Database (AxDTWH) to an Azure Data Lake and of course in a CDM folder.
Some features are not yet all available but in Release Wave 1 of 2020, all feature will be UP in production. But the main features are already OK and you can use it like : Entity Store to ADLS (full push and trickle feed for incremental update)
Also, a new feature will come in March 2020 ! And really a good news since if you are (like me) with a Customer in D365 FinOps (in Cloud) you don’t have access to the SQL Database and now Microsoft will bring the capacity to put your AX Tables to Azure Data Lake !
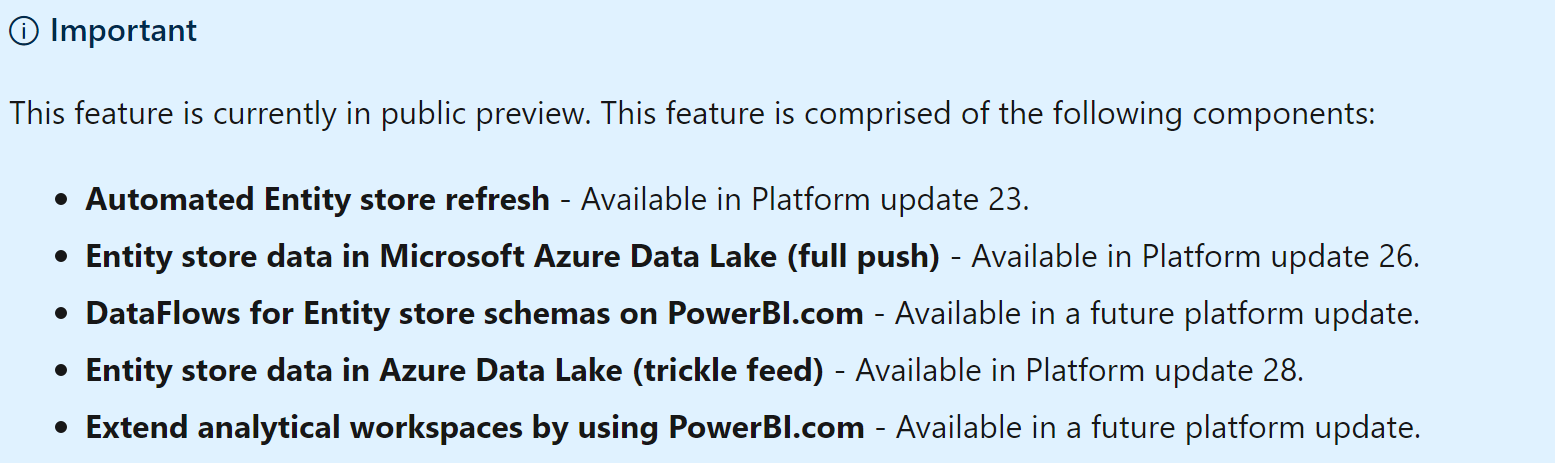
Automated Entity store refresh
You need to enable automated Entity store refresh before enabling Data Lake integration.
Go to System administration > Set up > Entity store.
On the Entity store page, a message indicates that you can switch to the Automated Entity store refresh option. This option is managed by the system. An admin doesn't have to schedule or monitor the Entity store refresh.
Select Switch now.

After the new experience is turned on, you can define the refresh for each aggregate measurement. The following refresh options are available:
Every hour
Twice a day
Once a day
Once a week
In addition, an admin can refresh any aggregate measurement on demand by selecting the Refresh button. Additional options will be added in future platform updates. These options will include options for real-time refresh.
Entity store data in Azure Data Lake (full push)
When this feature is turned on, Entity store data isn't populated in the relational Entity store database in the Microsoft subscription. Instead, it's populated in an Azure Data Lake Storage Gen2 account in your own subscription. You can use the full capabilities of PowerBI.com and other Azure tools to work with Entity store.
Before you start, you must complete these tasks in the Azure portal.
Create storage accounts. Provision a storage account in the same data center where your environment is provisioned. Make a note of the connection string for the storage account, because you will have to provide it later.
Create a Key Vault and a secret. Provision Azure Key Vault in your own subscription. You will need the Domain Name System (DNS) name of the Key Vault entry that you created. Also add a secret to Key Vault. As the value, specify the connection string that you made a note of in the previous task. Make a note of the name of the secret, because you will have to provide it later.
Register the app. Create an Azure Active Directory (Azure AD) application, and grant application programming interface (API) access to Key vault. Make a note of the application ID and its application key (secret), because you will have to provide them later.
Add a service principal to Key Vault. In Key Vault, use the Access policies option to grant the Azure AD application Get and List permissions. In this way, the application will have access to the secrets in Key Vault.
The following sections describe each task in more detail.
Create storage accounts
In the Azure portal, create a new storage account.
In the Create storage account dialog box, provide values for the following parameter fields:
Location: Select the data center where your environment is located. If the data center that you select is in a different Azure region, you will incur additional data movement costs. If your Microsoft Power BI and/or your data warehouse is in a different region, you can use replication to move storage between regions.
Performance: I recommend that you select Standard.
Account kind: You must select StorageV2.
In the Advanced options dialog box, turn on the “Data Lake Storage V2 : HNS Namespace to Enable”
Select Review and create. When the deployment is completed, the new resource will be shown in the Azure portal.
Select the resource, and then select Settings > Access keys.
Make a note of the connection string value, because you will have to provide it later.
Create a Key Vault and a secret
In the Azure portal, create a new Key Vault.
In the Create key vault dialog box, in the Location field, select the data center where your environment is located.
After Key Vault is created, select it in the list, and then select Secrets.
Select Generate/Import.
In the Create a secret dialog box, in the Upload options field, select Manual.
Enter a name for the secret. Make a note of the name, because you will have to provide it later.
In the value field, enter the connection string that you obtained from the storage account in the previous procedure.
Select Enabled, and then select Create. The secret is created and added to Key Vault.
Register the app
In the Azure portal, select Azure Active Directory, and then select App registrations.
Select New application registration, and enter the following information:
Name: Enter the name of the app.
Application type: Select Web API.
Sign-on URL: Copy the root URL and paste it here.
After the application is created, select it, and then select Settings.
Select the Required permissions option.
In the dialog box that appears, select Add option, and then select Add API.
In the list of APIs, select Azure Key Vault.
Select the Delegated permissions check box, select to grant permissions, and then select Done to save your changes.
On the Application menu of the new app, select Keys.
In the Key Description field, enter a name.
Select a duration, and then select Save. A secret is generated in the Value field.
Immediately copy the secret to the clipboard, because it will disappear within one or two minutes. You will have to provide this key to the application later.
Add a service principal to Key Vault
In the Azure portal, open Key Vault that you created earlier.
Select Access policies, and then select Add to create a new access policy.
In the Select principal field, select the name of the application that you previously registered.
In the Key permissions field, select Get and List permissions.
In the Secret permissions field, select Get and List permissions.

Work in Entity store in a Data Lake
Go to System administration > Set up > System parameters.
On the Data connections tab, enter the following information that you made a note of earlier in this topic:
Application ID: Enter the application ID of the Azure AD application that you registered earlier.
Application Secret: Enter the application key (secret) for the Azure AD application.
DNS name: Enter the DNS name of Key Vault.
Secret name: Enter the name of the secret that you added to Key Vault together with connection string information.
Select the Test Azure Key Vault and Test Azure Storage links to validate that system can access the configuration information that you provided.
Select the Enable data connection check box.

Entity store data should now be populated in the storage location that you provided, not in the relational Entity store database.
The aggregate measurements and refresh options that you select in the Entity store UI should now apply to data that is copied to Data Lake.
Here is my example below with my own Data Lake. Of course you can now connect your PowerBI DataSet to this CSV files with the connector Azure Data Lake Storage.

5. Azure Data Lake with AI : Dynamics 365 Customer Insights
The new AI Business Apps Customer Insights is already based on a Architecture with an Azure Data Lake Storage behind the scene.
You have 2 options : first one is to store your data to an Azure Subscription handle by Microsoft directly or you could also store it directly to your own Azure Subscription. It depends on what you want achieve and perhaps also the cost, since if you bring your own ADLS, you will pay for it (but as already known in the article, the cost of this type of storage is quite low)
I will give you the advice to store it to your own subscription, since it will be more powerful to have a control over the data and maybe achieve more for Data Scientists and prepare your data with Synapse Analytics, Data bricks and Azure ML. Because for an AI Apps, the main goal is of course to get some useful Insights. This Customer Data Platform (CDP) will have a focus on Customer Side to get an unify Contact model but also to get segmentation based on some measures and sometimes based on predictive measure. So, if you have access directly to your main ADLS with other sources and other Entities of your CDM, it could be useful to analyze it. Furthermore, output dataset (like dynamic segmentation) can be direclty connected with your CDM to an external Marketing App (like Adobe)
ALSO, main limitation of Customer Insights is to have only 4 refresh for all your datasources. If you manage your own ADLS, you could refresh on your own the DATA source for some sources when you need some near real time stuff. Like with StreamAnalytics, Cognitive Services, IoT Hub.
To achieve, go to your CI Apps and select Environments :

After, select : Save All Data to => Azure Data Lake Storage Gen2 :

Now your CI App will store all DATA to your own ADLS.
Also, for getting sources, you can select to get DATA from your CDM folder in your ADLS. So like I Said, your Data Lake is your MAIN Data Management Platform (DMP) . So for my previous chapter talking about Entity Store with Dynamics 365 FinOps I can get the CDM folder created for PowerBI but can be used for Customer Insights of course. So, select Connect to CDM folder :
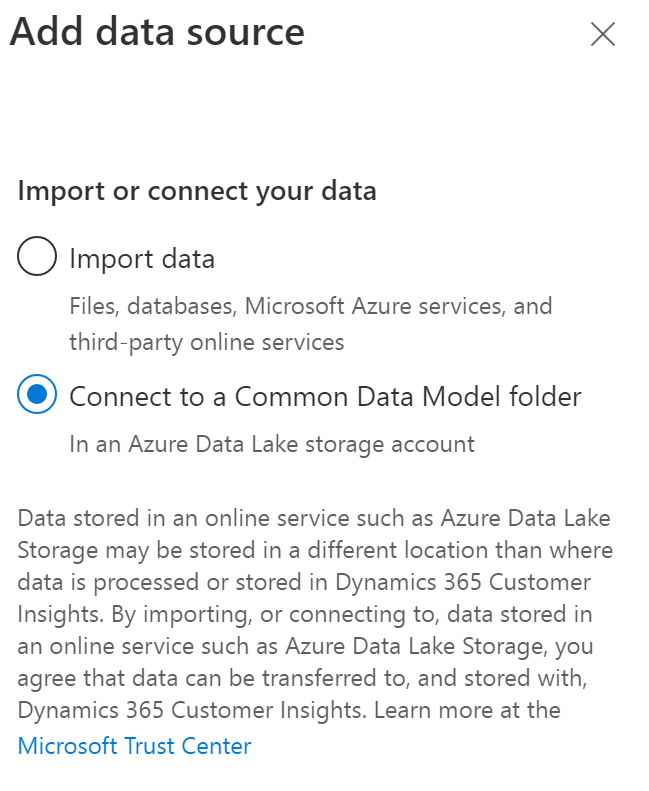
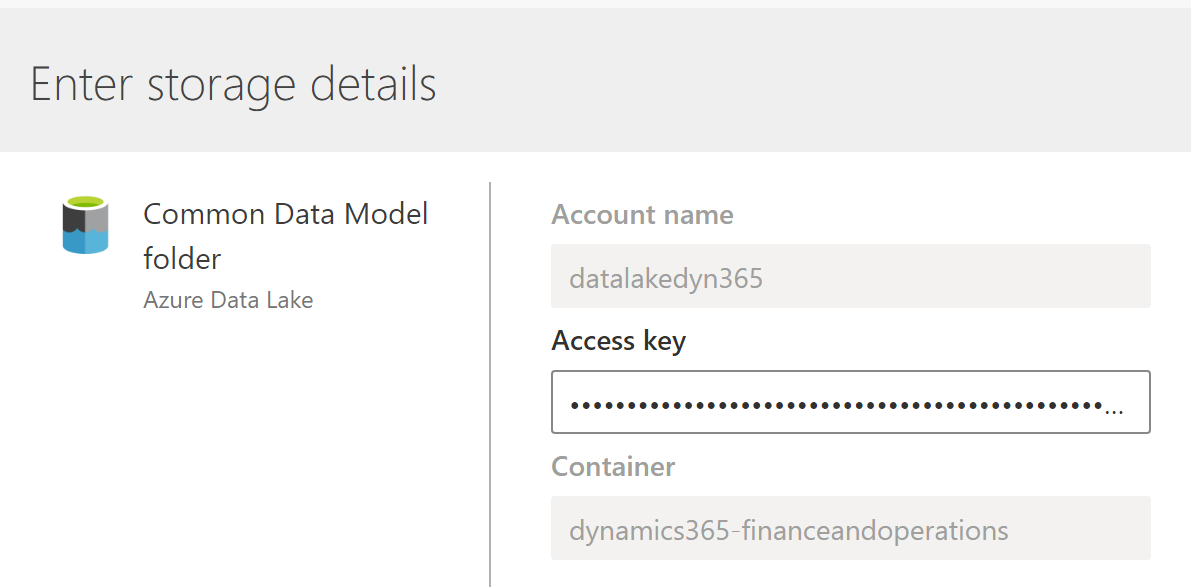
Connect to your own ADLS

And now I have without coding anything, my datasources from my ERP system. I can also add now other data coming from my CDM like PowerApps, Dynamics 365 for Sales, POS System coming from Dynamics 365 Commerce etc…
If you want to achieve more :
Azure Databricks connector with ADLS : https://docs.databricks.com/data/data-sources/azure/azure-datalake-gen2.html
Azure ML (Prepare dataset) on ADLS with Python and U-SQL : https://docs.microsoft.com/en-us/azure/machine-learning/team-data-science-process/data-lake-walkthrough
Azure SQL DW / Synapse with ADLS : https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-load-from-azure-data-lake-store
Overview of Synapase Analytics dashboard : https://azure.microsoft.com/en-us/services/synapse-analytics/
Copy and transform your DATA from your ADLS with Azure Data Factory (my loved ETL system at the moment) : https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-data-lake-storage
6. Azure Data Lake with Event Messaging : Stream Analytics
Azure Stream Analytics is a real-time analytics and complex event-processing engine that is designed to analyze and process high volumes of fast streaming data from multiple sources simultaneously. Patterns and relationships can be identified in information extracted from a number of input sources including devices, sensors, clickstreams, social media feeds, and applications. These patterns can be used to trigger actions and initiate workflows such creating alerts, feeding information to a reporting tool, or storing transformed data for later use. Also, Stream Analytics is available on Azure IoT Edge runtime, and supports the same exact language or syntax as cloud.
The following scenarios are examples of when you can use Azure Stream Analytics:
Analyze real-time telemetry streams from IoT devices
Web logs/clickstream analytics
Geospatial analytics for fleet management and driverless vehicles
Remote monitoring and predictive maintenance of high value assets
Real-time analytics on Point of Sale data for inventory control and anomaly detection
How does Stream Analytics work?
An Azure Stream Analytics job consists of an input, query, and an output. Stream Analytics ingests data from Azure Event Hubs, Azure IoT Hub, or Azure Blob Storage. The query, which is based on SQL query language, can be used to easily filter, sort, aggregate, and join streaming data over a period of time. You can also extend this SQL language with JavaScript and C# user defined functions (UDFs). You can easily adjust the event ordering options and duration of time windows when preforming aggregation operations through simple language constructs and/or configurations.
Each job has an output for the transformed data, and you can control what happens in response to the information you've analyzed. For example, you can:
Send data to services such as Azure Functions, Service Bus Topics or Queues to trigger communications or custom workflows downstream.
Send data to a Power BI dashboard for real-time dashboarding.
Store data in other Azure storage services to train a machine learning model based on historical data or perform batch analytics.
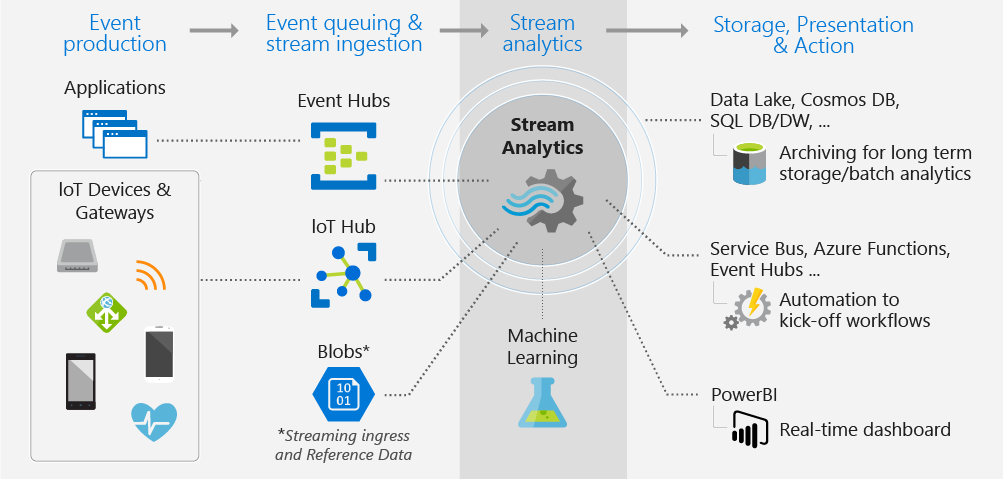
The image shows how data is sent to Stream Analytics, analyzed, and sent for other actions like storage or presentation:

The input can be IoT Hub or Event Hub like getting data from Twitter API or also getting sensors data from your IoT Devices (like for Field Service of Dynamics 365) for predictive maintenance.

… And the ouput ! And yes of course a direct connector to your own Azure Data Lake Storage ; and put this DATA to your CDM folder.
In the middle of this workflow you can do some queries and also call an Azure ML API to put some insights before putting the DATA in your ADLS.
And you could achieve this kind of Architecture that I already used a lot with a Cold and Hot flows :

7. Azure Data Lake with Power BI Dataflows
PowerBI Dataflows is the future of BI… the new self-service data preparation.
As data volume continues to grow, so does the challenge of wrangling that data into well-formed, actionable information. We want data that’s ready for analytics, to populate visuals, reports, and dashboards, so we can quickly turn our volumes of data into actionable insights. With self-service data prep for big data in Power BI, you can go from data to Power BI insights with just a few clicks.
Here is the architecture :

Power BI introduces dataflows to help organizations unify data from disparate sources and prepare it for modeling. Analysts can easily create dataflows, using familiar, self-service tools. Dataflows are used to ingest, transform, integrate, and enrich big data by defining data source connections, ETL logic, refresh schedules, and more. In addition, the new model-driven calculation engine that's part of dataflows makes the process of data preparation more manageable, more deterministic, and less cumbersome for data analysts and report creators alike. Similar to how spreadsheets handle recalculations for all affected formulas, dataflows manage changes for an entity or data element on your behalf, automating updates, and alleviating what used to be tedious and time consuming logic checks for even a basic data refresh. With dataflows, tasks that once required data scientists to oversee (and many hours or days to complete) can now be handled with a few clicks by analysts and report creators.
Data is stored as entities in the Common Data Model in Azure Data Lake Storage Gen2. Dataflows are created and managed in workspaces by using the Power BI service.
Dataflows are designed to use the Common Data Model, a standardized, modular, extensible collection of data schemas published by Microsoft that are designed to make it easier for you to build, use, and analyze data. With this model, you can go from data sources to Power BI dashboards with nearly zero friction.
You can use dataflows to ingest data from a large and growing set of supported on-premises and cloud- based data sources including Dynamics 365, Salesforce, Azure SQL Database, Excel, SharePoint, and more.
You can then map data to standard entities in the Common Data Model, modify and extend existing entities, and create custom entities. Advanced users can create fully customized dataflows, using a self-service, low- code/no-code, built-in Power Query authoring experience, similar to the Power Query experience that millions of Power BI Desktop and Excel users already know.
Once you’ve created a dataflow, you can use Power BI Desktop and the Power BI service to create datasets, reports, dashboards, and apps that leverage the power of the Common Data Model to drive deep insights into your business activities.
Dataflow refresh scheduling is managed directly from the workspace in which your dataflow was created, just like your datasets.
Uses For Dataflows
The immediate use that comes to mind for me is the ability to standardise access to source data. Up until now, when I create a new Power BI Desktop file, I have always connected back to the original data source and loaded the data I needed for the new PBIX file. Often the data needed to be transformed, so I performed some transformation steps in Power Query before loading. Then, later on, when I needed to create a new workbook, I had to either copy the Power Query steps or re-write the steps again from scratch. Each person in the same organisation with the same need for the same data had to do this too hence multiplying the rework. You can imagine that there is the potential to have many versions of the same thing. With dataflows all that changes. One person can create a single dataflow and make it available via an App Workspace. Anyone with access to that App Workspace can then directly access the table of data directly from that dataflow (demo to follow).
Other benefits include:
Effectively creating an online centralised data mart/data warehouse for storage of data in a format that is better suited to reporting and analytics than the source data.
As new dataflow connectors become available, it will be easier than ever to connect to important data such as “customers” from services such as MS Dynamics 365. I have tried to do this myself in the past and found it far to complex for the average business user. This is all about to change.
Dataflows have incremental refresh (currently just for premium) meaning that large data refreshes that currently can take a very long time to complete can be configured to refresh just the changes.

Here are some schemas to understand the whole process behind the Dataflow on PowerBI. And here we are, ADLS is again in the center of everthing !
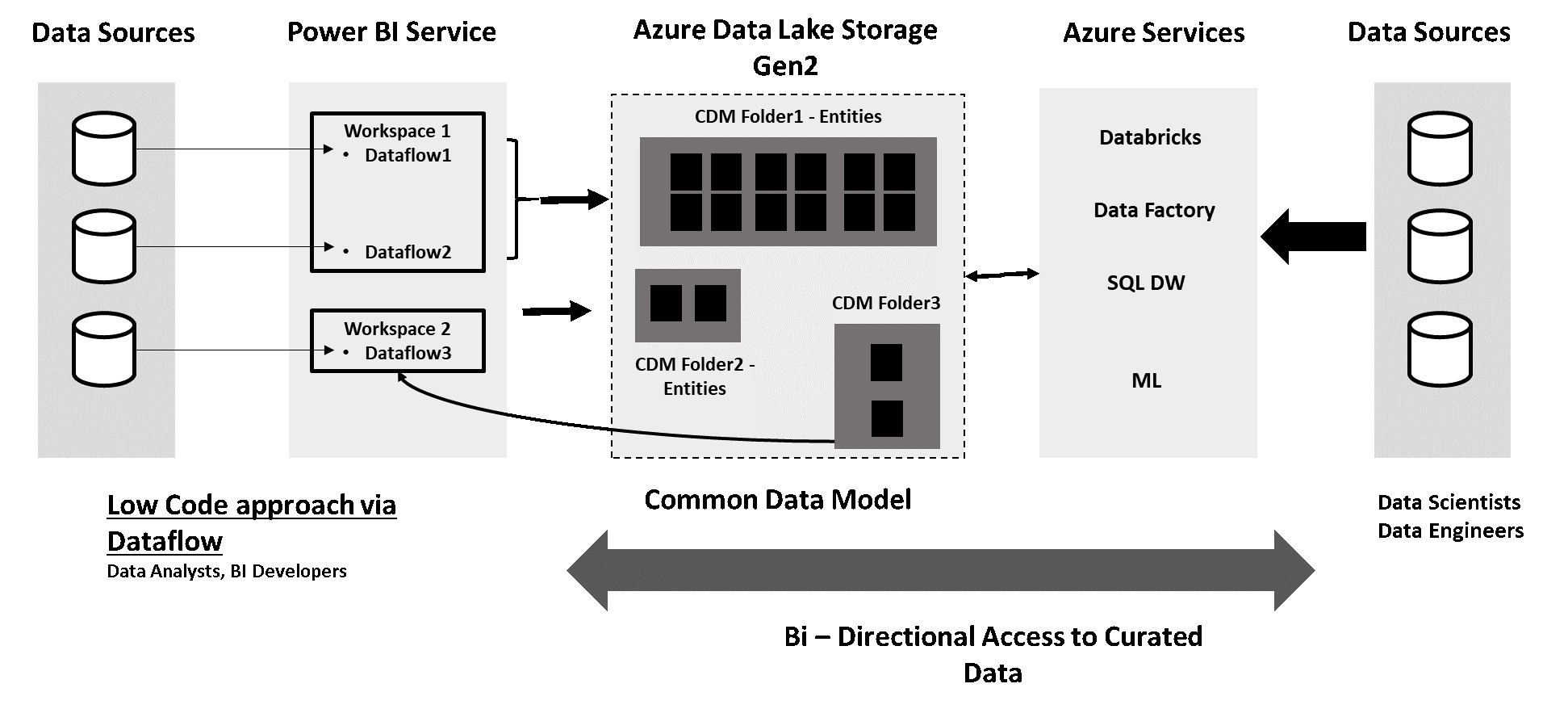
8. Azure Data Lake with Power Apps and Automate
Of course behind the PowerApps platform, you have Entities.
Theses Entities can be part of a Dataflow.
You can configure dataflows to store their data in your organization’s Azure Data Lake Storage Gen2 account
Dataflow with Analytical entities feature utilizes the Export to data lake service, which may offer varying levels of compliance, privacy, security, and data location commitments.
There are some advantages to configuring dataflows to store their definitions and datafiles in your data lake, including the following:
Azure Data Lake Storage Gen2 provides an enormously scalable storage facility for data.
Dataflow data and definition files can be leveraged by your IT department's developers to leverage Azure data and artificial intelligence (AI) services as demonstrated in the GitHub samples from Azure data services.
It enables developers in your organization to integrate dataflow data into internal applications and line-of-business solutions, using developer resources for dataflows and Azure.

You have also an another feature : The Export to data lake service enables continuous replication of Common Data Service entity data to Azure Data Lake Gen 2 which can then be used to run analytics such as Power BI reporting, ML, Data Warehousing and other downstream integration purposes.
Export to data lake simplifies the technical and administrative complexity of operationalizing entities for analytics and managing schema and data. Within a few clicks, you will be able to link your Common Data Service environment to a data lake in your Azure subscription, select standard or customer entities and export it to data lake. All data or metadata changes (initial and incremental) in the Common Data Service are automatically pushed to the Azure data lake gen 2 without any additional actions.


For Power Automate, you have of course a connector. Well I think I didn’t say to someone : “you don’t have a connector for that…” :)

You have a large list of functions and of course you can append a file, select one to read it and upload a new one to your CDM in your ADLS.

Hope you will see that ADLS is really the future in the Microsoft Ecosystem !
To conclude this article, a special quote from the Ignite Tour !
“Azure Data Lake includes all the capabilities required to make it easy for developers, data scientists, and analysts to store data of any size, shape, and speed, and do all types of processing and analytics across platforms and languages. It removes the complexities of ingesting and storing all of your data while making it faster to get up and running with batch, streaming, and interactive analytics. Azure Data Lake works with existing IT investments for identity, management, and security for simplified data management and governance. It also integrates seamlessly with operational stores and data warehouses so you can extend current data applications. We’ve drawn on the experience of working with enterprise customers and running some of the largest scale processing and analytics in the world for Microsoft businesses like Office 365, Xbox Live, Azure, Windows, Bing, and Skype. Azure Data Lake solves many of the productivity and scalability challenges that prevent you from maximizing the value of your data assets with a service that’s ready to meet your current and future business needs.”